(This article originally appeared on Medium and is re-published here with Jon Barber’s permission.)
Quick note: I talk about all of this in the context of bug bounty, but the concepts apply to a lot of topics!
One of the things I’ve always found challenging about security, especially with bug bounty, is trying to remember, manage, and keep track of all the information there is to maintain. I like keeping notes on everything from bug bounty targets to tips and tricks regarding vulnerability classes, useful tools, exploits/payloads, etc. As you can imagine, it gets to be a lot.
Having an effective way of keeping track of all of this information has always seemed crucial. The problem was, none of my solutions seemed like they were solving the problem.
Problems with Notes
I’ve played around with a number of different ways for managing my notes in the past: classic folders with text files, personal wiki, OneNote, Google Docs, Evernote, etc.
Most recently, I had been using Notion for all of my notes. Notion is a relatively new tool for note taking and project management with a shiny UI. It utilizes a pretty standard directory-like hierarchy, but comes with the ability to easily tag and hyperlink pages. I thought it was pretty good, but I was still running into the same problems:
Duplicate notes
A really common problem with my notes was that I’d think, “Hmm, I don’t have any notes around X. I’ll make a page and jot some things down,” only to realize that I had already done this — it was just in a different place in my notes.
Other times I’d have some notes I’d want to store, but wasn’t sure which page I should put them on because it was relevant to multiple pages. Do I copy the same thing to each? But what happens if I want to make changes to all of them? Do I try to hyperlink between each?
Lost notes
There’s nothing more frustrating than stumbling across a page of notes that would have been helpful a month ago. I kept finding that I’d make a note of something useful to “avoid forgetting it,” and then would never reference the note again. If I didn’t store that tidbit of knowledge close to something that would cause me to re-see it, I’d often forget I ever wrote it down.
It made me question why I was bothering to take notes in the first place. I needed a solution that would more effectively “push” notes up to me when I was browsing something related.
Messy notes
The latter two problems partially stem from a lack of good structure. But how am I supposed to structure something as unstructured as thoughts and knowledge? Setting up an imperfect structure that later requires a reorganization is a painful and inefficient process.
I wanted something with a more “fluid” structure. One that would adapt to how I was taking notes, not vice versa.
In October of 2019, I started seeing repeated mentions on Twitter of people raving about this new note taking tool. Having tried so many, I was initially skeptical. But I trusted the people who were talking about it, so I started learning more.
It didn’t take long for me to realize RoamResearch was a game changer.
Why Roam?
At its core, Roam is just another note taking app with one key difference: bidirectional linking. Most note taking solutions utilize a “hierarchical tree” for organizing everything. To illustrate this, I’ll use a simplified version of my notes as an example. Previously, my bug bounty notes would be organized roughly like this:
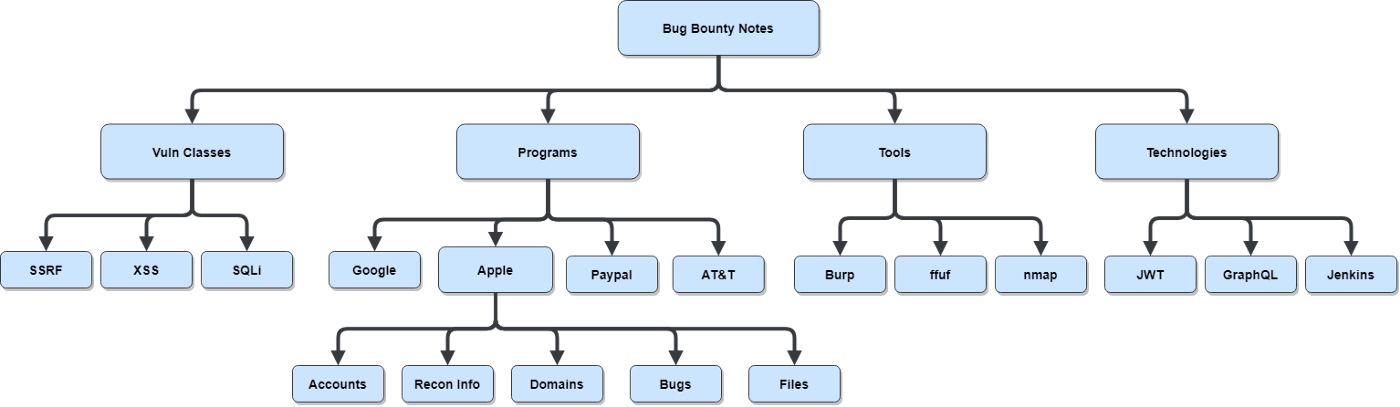
Each of these would be directories containing text files, images, code, etc. There might be some way to hyperlink between directories, but ultimately everything is nested hierarchically.
In Roam, the same data is structured like this:
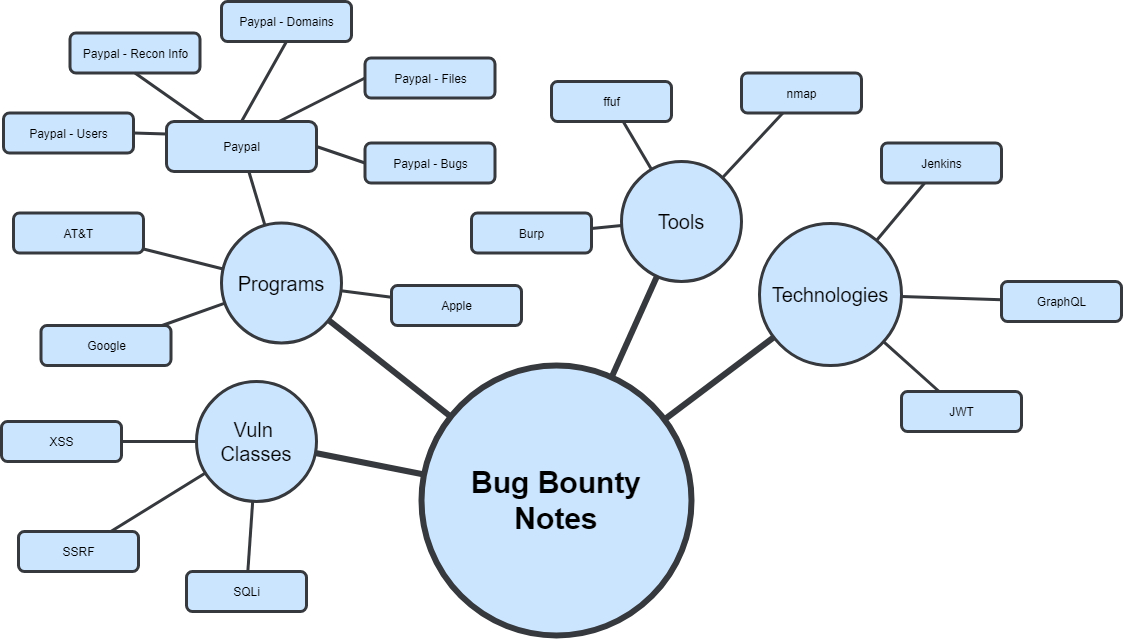
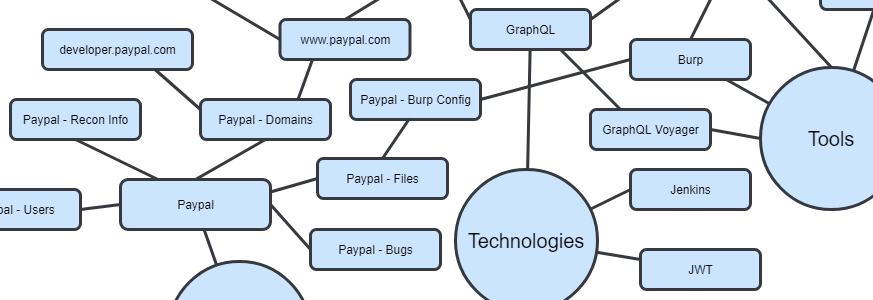
At first glance, these two images look almost identical, but the key difference here is that we have a graph-based approach instead of a hierarchical one. The benefit of a graph is that we’re not limited to a single parent-child relationship for nodes. Any of the nodes in Roam can point to any other node.
For example, if I find a subdomain on a program that has a GraphQL endpoint, I’ll link it to the general GraphQL technology page. If a new GraphQL tool comes out, I’ll link it to the Tools page, but then I’ll also link it to the GraphQL page. From the GraphQL page, I can easily see all the GraphQL endpoints I’ve found in various programs to test the tool against. I don’t need to worry about duplication because one node can link to multiple other nodes. As these connections are made, we start seeing the graph start to come to life:
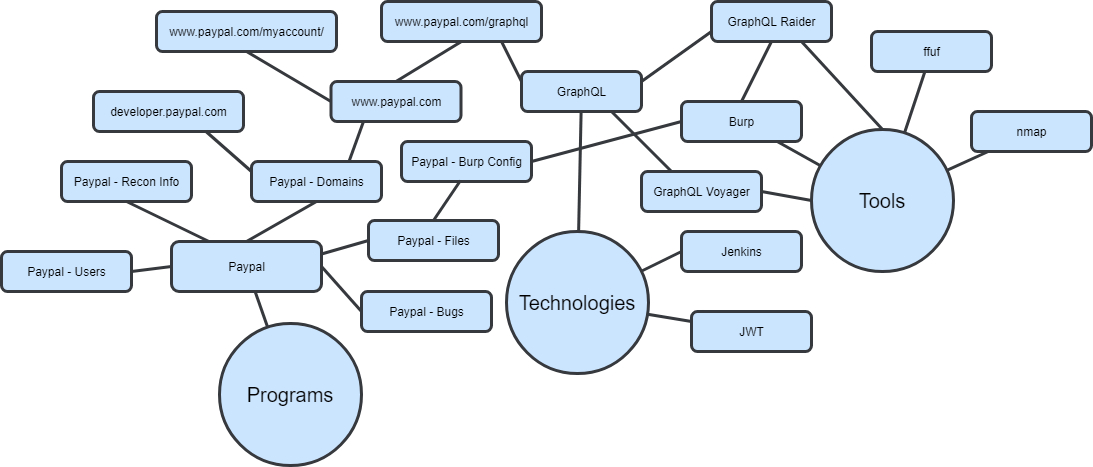
As you keep making more and more connections, you eventually get something like my current Roam database:
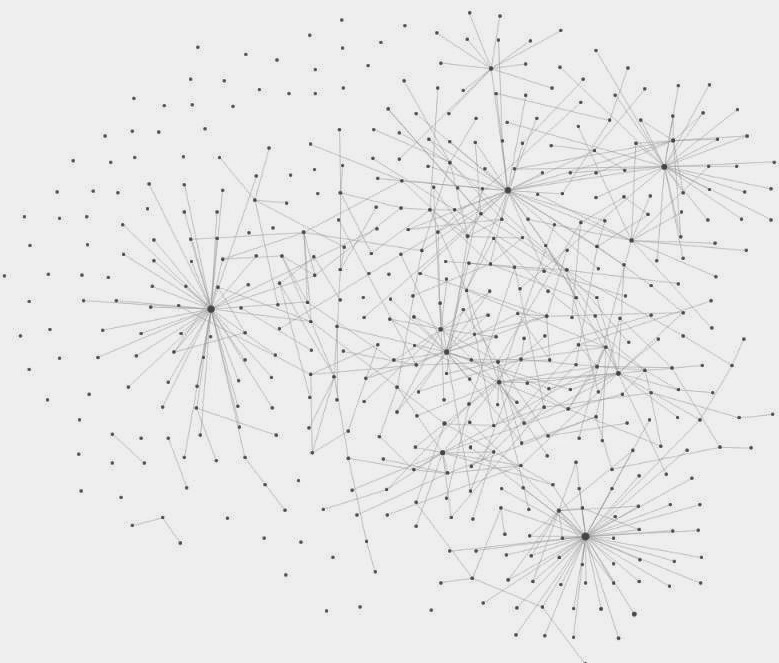
There are natural hierarchies that form, but many of them almost “overlap” with each other based on how closely they’re related. I can spend less time worrying about the structure of things, as the structure is essentially determined by the links between pages.
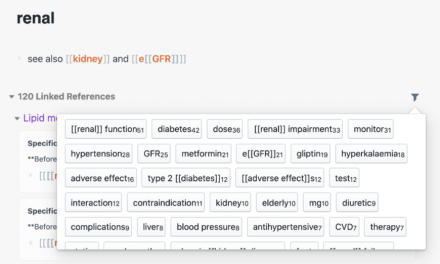
As long as you link a page with a few others, it’s far less likely something will get lost. At the bottom of every page, Roam will display all of the linked pages as well as “unlinked” ones, which are places where the page title has been used in the text of the page. This significantly helps discoverability.
Part of Roam’s power is how low-friction it is to make links between pages. You link one page to another by tagging it using the syntax of either #page or [[page]]. I won’t go too deep on what makes the Roam UX so good, as many others have already done great write-ups on this subject; if you’re curious, check out this thread:
#roamcult thread of threads https://t.co/VHjBWO1trJ
— Roam Research (@RoamResearch) December 9, 2019
Instead, I’m going to focus on some effective ways I’m currently organizing and linking various pieces of bug bounty knowledge in Roam. There are 4 major areas most of my information falls into : Programs, Vulnerability Classes, Technologies, and Tools.
Programs
For each bug bounty program I participate in, I start with the main program page. Since each page in Roam needs a unique title, I use the naming convention of Company-BB-Program. This page is a good place to add notes around program policy, scope, pointers, etc. I’ll then link to the following 5 sub pages (each with the prefix of Company-BB-):
Domains
Here I’ll create links to subpages for each of the in scope domains. For example, here’s what a basic page for PayPal looks like based off their HackerOne scope:
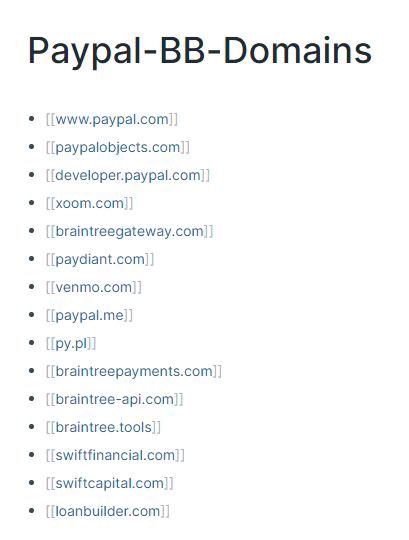
I’ll then create subpages in each of these with the full URL for keeping track of interesting endpoints. I’ll keep track of functionality, what I’ve tried, what looks interesting, etc. These pages will frequently get tagged in each of the following sections.
Recon
One of the most important parts of assessing any organization is doing thorough recon. It helps build your mental model of the target, can lead you to resources that help you better understand their tech stack, and sometimes just straight up leads you to a bug.
I spend significantly more time doing recon than actually attacking anything.
— n a f f y | supreme leader (@nnwakelam) October 2, 2016
It’s important to take notes about what you find in the reconnaissance phase, as it’s easy to forget small details that can be very valuable in the future. Many of the things you find while doing recon don’t fit into the domain-specific pages. I’ll use this space to note things like:
- Conference talks given by the company
- API Documentation
- Company/Employee Github accounts
- Engineering blog posts
Bugs
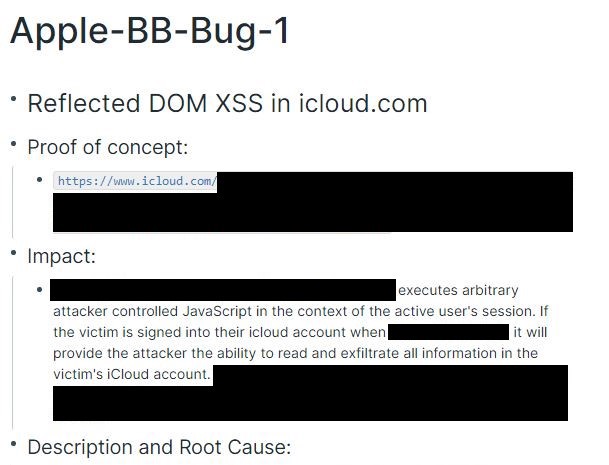
Once I’ve found a bug, I’ll create a subpage here using the naming scheme of Company-BB-Bug-1. I’ll do my writeup on this page, which generally consists of Proof of Concept, Impact, and Description and Root Cause. I’ll also use this page for keeping track of submission status. For really sensitive bugs, I’ll just store a PGP encrypted copy of the bug here as Roam is still a cloud hosted tool at the end of the day, but they currently have End to End Encryption for blocks in the alpha.
Alpha feature:
End to End Encryption for blocks, with specific passphrases to view
For encrypted blocks, your text and passphrase are never sent to our servers without first passing encryption (see right img)
Forget the passphrase, you lose the content of the blocks though pic.twitter.com/o3kdN2xBFd
— Roam Research (@RoamResearch) January 28, 2020
Possible Bug
It’s pretty common to come across something that might be a bug, but isn’t quite there yet. For example, maybe you need a second bug to chain it into something impactful. Maybe you need more context around the application to understand if it’s a problem. Either way, it’s important to note it down so that you don’t forget about it. I utilize this page a lot for this purpose.
Follow Up
When doing testing, I’ll often spot things that look interesting or have my spidey senses tingling, but I recognize it’s a rabbit hole I don’t have time for, or it’ll distract me from what I’m currently looking at. Whenever that happens, I’ll make a note here so that I can come back to it later. This page can also make it easy to jump back into a program after taking time off.
Vulnerability Classes
These next three sections are for building a “knowledge library” of security information. Here I create links to every class of bug I come across. Whenever I read a good bug writeup, blog post, or tip related to a bug class, I’ll add them to that vulnerability class’s page. Especially when it comes to things like bypasses to common protections, having all those tips organized in a consistent location is super valuable.

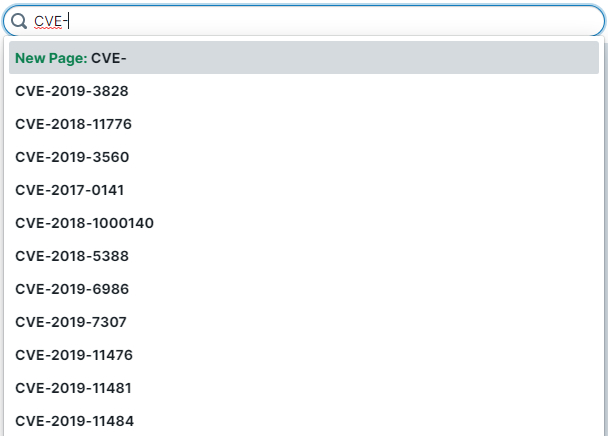
CVEs
Another really useful thing I’ve been doing here is creating pages for every exploitable CVE. I’ll add notes about how to exploit it, known tools or payloads, limitations, etc and then link to the appropriate vulnerability class and technology involved. Then whenever I find something is vulnerable to a given CVE, I can just pop it into the search box and see if I have any existing notes for it.
Technologies
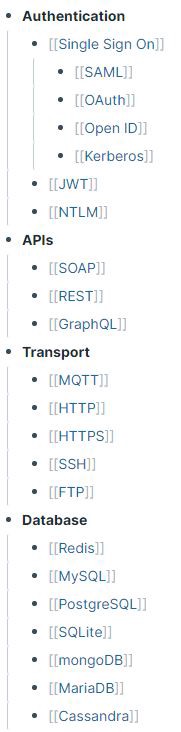
There are an absurd number of different technology stacks utilized by companies these days. Each one has its own unique security and privacy concerns. Trying to remember all of this is a futile effort, so I find it useful to create a page for each where I can dump relevant knowledge into as I come across it.
For example, when browsing things like #bugbountytips on Twitter, I’ll add useful techniques for a given technology to its page. Then when I come across that technology in the wild, I have a list of useful tips and tricks for it. I’ll also link these pages to specific vuln classes, CVEs and tools as appropriate.
Tools
Similar to the above, any time I find a new tool that could be useful, I create a page for it and then link it to the appropriate vulnerability class or technology. I’ll use this page to add notes about setup, usage, limitations etc; however, many of these are simply just links to the tool’s GitHub page. My main goal here is to simply keep track of tools so that I’m aware of them when I might need them.
Conclusion
I hope to share some of my notes with the community in the future, but figured this would be a useful start. I do think it’s valuable to have your own customized notes, especially in something like Roam that leaves so much room for personal style. Hopefully you’ve found this useful. I’m constantly evolving how I’m using Roam, so if you have any tips or advice for how you think things could be done better, please share. If you have any questions or would like clarification on anything, don’t hesitate to reach out to me on Twitter @bonjarber!