RoamBrain has started a new site, RoamPublic.com, which aims to provide a directory of all the available public texts which are formatted for Roam. Here Rishi Tripathy explains the process he used to make the text of the Mahabharata ready for inputting into a Roam database.
A few weeks ago, co-founder of Roam Conor White-Sullivan tweeted that there were some Roam accounts up for grabs for people who were willing to transcribe some major texts into Roam.
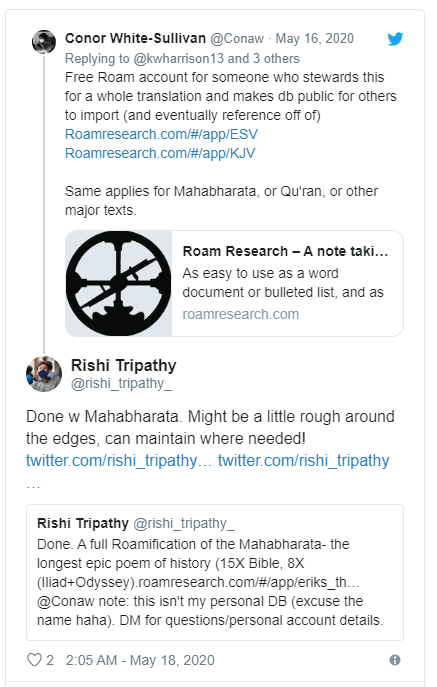
As a recently–graduated college student in quarantine, I figured I could make a weekend out of the project that would hopefully pay dividends in the long term.
Many of the shorter texts were already taken, so I decided to take my heritage by the horns and tackle the longest Sanskrit text and one of the longest epics known to man or woman by Roamifying the Mahabharata. It is 15x the length of the Bible and 8x as long as the Iliad and Odyssey combined. Here is the Roam version.
In this article, I’ll dive into why this sort of project can be useful and how I hacked my way through it, (so that you can do something similar).
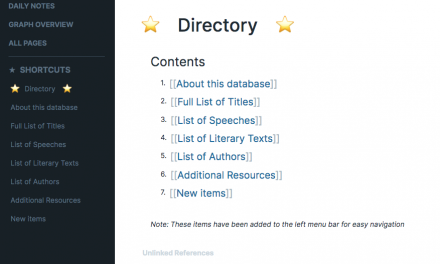
Contents
Tools I used
General notes
Step 1: Finding the files
Step 2: Processing the files to make them manageable to work with
Step 3: Transforming each file to be compatible with Roam import
Step 4: Saving the text as a markdown file and importing into Roam
Why is this useful?
Having a ‘community’ of significant texts as part of a Roam database has lots of power. For example, when studying a text in your own private database, you can instantly pull in relevant parts to your own notes and see what resonates with you, and use powerful filters and queries to identify where ideas, characters, or themes in the text intertwine.
In the mid- to long-term, when Roam becomes more collaborative, this sort of functionality will be able to create communities of study, answering questions like:
- What are all the ways that this passage is interpreted by different people?
- How does this passage differ between different translations or versions of a text?
- and many more.
The possibilities are endless.
The way that I approached this Roamification was to create a relatively clean slate from which to work off of, which can be exported into other databases to work on in personal study, and hopefully eventually used as a central source of truth for people to link their own understanding of the Mahabharata to and from.
How I hacked it
In my implementation of the project, I took an open-source copy of the Mahabharata, did some processing on the file, and imported it into my Roam database.
Tools I used
These were the tools I used:
- Chrome + the Project Gutenberg open press
- Sublime Text – feel free to use any text editor you like to do find-and- replaces (the bulk of my processing work)
- Regex 101– a tremendous tool and resource for testing regular expressions. Measure strings twice, and cut them once!
- Roam – of course!
- Twitter for inspiration on how others had formatted/structured their large texts.
You can see my GitHub repo of this project and this demo (under the Demo subfolder) here. It also includes all of the regex examples I cite in my step-by-step overview. You can also follow along with individual commits.
General notes
My process was made considerably harder because the Mahabharata and each of its Parvas is so ridiculously long.
This, coupled with the fact that Roam’s markdown import doesn’t work on files that seem to be bigger than 500 KB, meant that, at times, I had to cut/divide and re-merge content to make it work. I did this utilizing some hacks, and though it worked out pretty alright (and sufficient for my needs), it was tedious.
I think that there are more standard script-based methods for doing regex processing that might be more effective if you have lots of different texts you want to process.
That said, here are the four steps that I took to Roamify the Mahabharata.
Step 1: Finding the files
I found this copy of the Mahabharata open-sourced from the Gutenberg Project. I saved this file as a .txt locally in its own folder.
Step 2: Processing the files to make them manageable to work with
The Mahabharata is an exceptionally long piece of text (even the Gutenberg Project has it divided into four volumes). For the purposes of this demo, I’ll only be working with the first volume but, even within the first volume, it was important that I split the original file into multiple files to make it easier to work with. The “Volume One” file I got from the Gutenberg Project contained the first three Books, or Parvas, of the Mahabharata, so I split the file into individual files by cutting and pasting, delimited by the word “BOOK”, leaving each Book/Parva in its own .txt file.
I removed footnotes since I was concerned only with the original translated text.
While doing this, I factored out the translator credits and license information to their own files as well (which you can see in the finished product).
This let me have manageable chunks that were easier to work with. I also reformatted the header of each file to something concise, consistent and recognizable, and did this in each book.
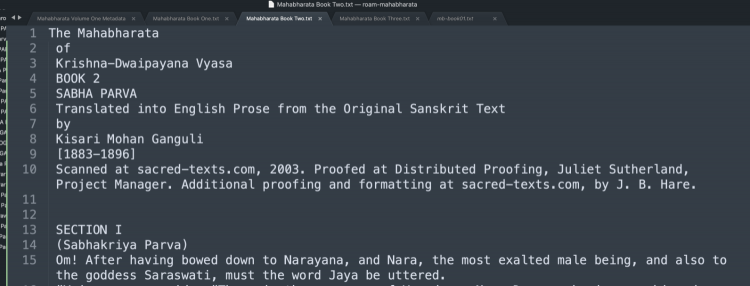
Book heading – Before
Book heading – After
I suggest that, when dividing your text into different files, you have each text file be < 500 KB to avoid issues during Markdown import to Roam.
Don’t do this!
If you’re using Sublime or another text editor, also be sure to turn syntax highlighting off or work with files as .txt until the end. I ran into issues with my CPU slogging to a halt and Sublime freezing when I tried to do big find-and-replace operations, and I had to force-quit the app multiple times. To avoid this, do your operations on one file at a time. (This will only be an issue if your text is really, really long.)

The first processing step I wanted to do was to remove these weird line breaks from the original. Phrases were spaced over multiple lines, seemingly, due to some width constraint.
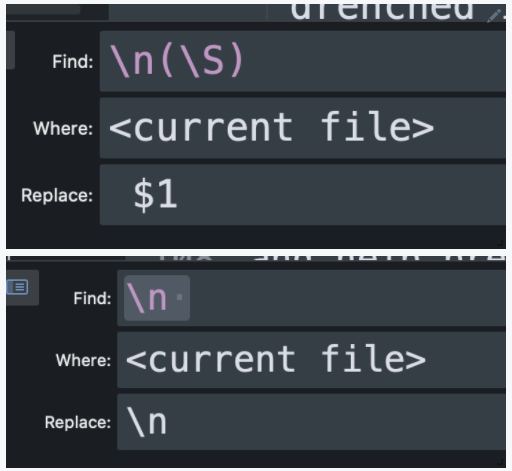
To do this, I used this sequence of two find-and-replaces, applied in each file individually to prevent freezing. Remember the space in front of the capture group $1!
Now we have each Book in its own file, and each verse of each section on its own line!
Step 3: Transforming each file to be compatible with Roam import
These are the individual steps I followed:
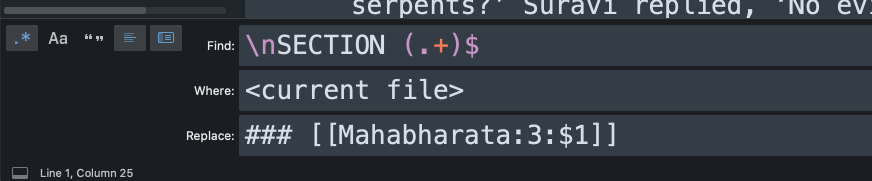
a) Give each section its own page and H3 header. In each file, apply the following find-and-replace:

This takes each part of the text that delimits a SECTION and puts it into a tag with the <TEXT_NAME>:<BOOK_NUMBER>:<SECTION_NUMBER> format.
Depending on how your text is structured, you can be creative with how you want to divide the tag structure. For each book (since each book lives in a separate file), substitute the actual digit for the BOOK_NUM placeholder, as such:
b) Give each book an H1 header (manual). Since each book will be imported into its own page, it doesn’t need to be in a tag. This is completely optional and I only did it because I liked how it looked in Roam, though it does help with indentation later (you want these lines to start with a # ). I also did this manually by just adding a - # to the first title line in each file.
c) Remove duplicate newlines (apply in each file) to the first title.
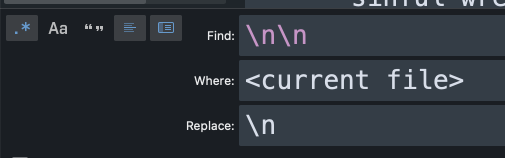
This is just to make it pretty. Repeat as needed!
d) Replace “bad quotes” with normal quotes.
In my sourced text, there were weird ‘smart quotes’ that were used as single and double quotation marks: “ ” and ‘ ’ instead of ” ” and ‘ ‘.
This is how I removed them (replace in each file to prevent slowdowns).


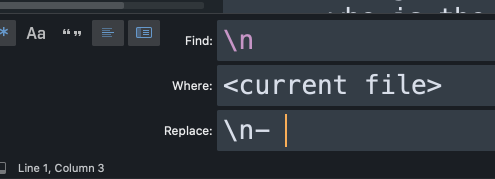
e) Give every line a Roam bullet point.
Again, apply in each file if you have multiple files. Remember the space after the hyphen!
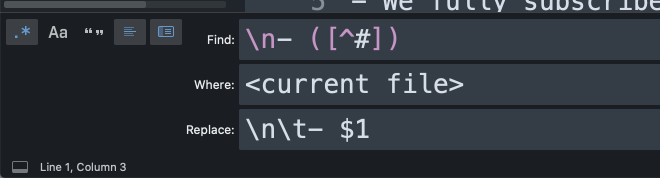
f) Indent every line in a Section underneath the Section header.
This takes every line that isn’t a header (section or book title) and tabs it in so that we can get a collapsible view of each section and the correct lines are nested under each header when imported to Roam.
Step 4: Saving the text as a markdown file and importing into Roam
Enter Cmd+shift+s and add a .md extension to each file. Now you have base .md files that can be directly imported into Roam! If your text is very, very long (or each individual file is >500 KB) it’s likely that some files may need to be split up and re–merged after import due to size constraints with Roam’s markdown importer.
You’ll know if a file is too big if a page looks like it imported successfully but then it’s blank once you click in.
To split and re–merge:
- split into multiple files on section gaps
- name them things like 1A, 1B,
- import, and
- re-merge so that all the sections can live on one page. (This step is optional, and probably shouldn’t be done if you want your text to be easily re-exportable for others!)
For more on how to import markdown files into your own Roam (or if you want to contribute to RoamPublic), you can check the help database, tweet at #roamcult on Twitter, or ask me! 🙂
Conclusion
This project was a fun little exercise in troubleshooting regexes and pushing the limits of find-and-replace and Sublime. It was also a fulfilling one because now I know that people are using my Roamification to amplify and improve their own study of the Mahabharata. Again, you can find the final product here, and a Github repo with the demo regexes from this article here.
If I were to do something like this again, I think I would likely take the time to write a Python script that does the processing that I have outlined.
I will note, however, that the source of your text and its original formatting will have a huge impact on what steps you need to take to get it from its original format to one that’s able to be moved into Roam cleanly.
I hope that this has been helpful and informative! If you’re wondering how to bring texts into Roam either in the public domain on RoamPublic or for your own personal use, give me a shout! My DMs are open if you have questions! Happy Roaming!