
Synthesis is fundamental to knowledge work. It also happens to be one of the goals of Roam Research!
In this short post, I want to explain Roam’s superpower for knowledge synthesis from a theoretically grounded point of view. Fortunately, in my day job I am an Assistant Professor of Information Studies and Human-Computer Interaction, and my areas of specialty are creativity support systems and tools for thought. So I’ll draw on my academic research on interactive systems for knowledge synthesis to do this.
In particular, I want to focus on the key barrier of formality, and how Roam has exciting ingredients for overcoming this barrier.
0. Key terms and scope
Let’s start by defining a key term and a scope for this post.
First, what is synthesis? I understand synthesis to be fundamentally about creating a new whole out of components (Strike & Posner, 1983).
This means that synthesizers need to be able to compose individual ideas (evidence, hypotheses, concepts, claims) into a larger conceptually integrated understanding, such as a theory or argument.
Second, what kind of synthesis am I interested in? I’m particularly interested in synthesis to support scholarly/scientific research, whether by traditional academic researchers, or researchers outside the academy (see, e.g., Bret Victor’s DynamicLand, or Andy Matuschak and Michael Nielsen’s work on tools for thought).
A typical form that scholarly/scientific synthesis takes is a literature review, but there are other more visual representations like causal models or diagrams. Here are some examples I like:
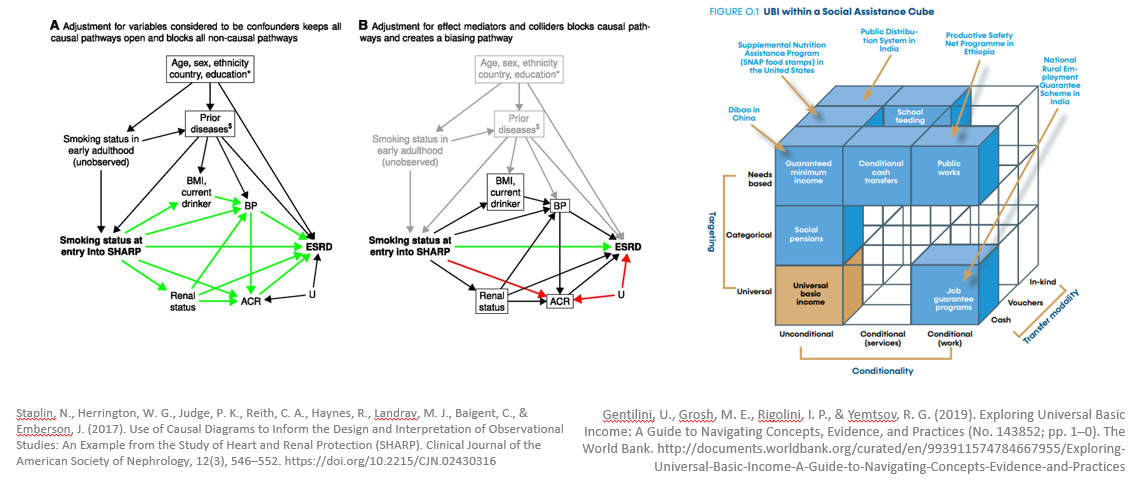
1. Synthesis requires formality
It’s important to notice something about these examples of synthesis representations: they go quite a bit further than simply grouping or associating things (though that is an important start).
They have some kind of formal semantic structure (otherwise known as formality) that specifies what entities exist, and what kinds of relations exist between the entities.
This formal structure isn’t just for show: it’s what enables the kind of synthesis that really powers significant knowledge work! Formal structures unlock powerful forms of reasoning like conceptual combination, analogy, and causal reasoning. This is a key part of the vision of projects like the Semantic Web.
Judea Pearl makes this point quite emphatically, sketching out a “Ladder of Causation” that puts mere associationist reasoning at the bottom, and sophisticated counterfactual causal reasoning at the top, which requires a rich causal model (one kind of formal structure).
Judea Pearl’s Ladder of Causation graphic can be found here.
2. Making tools for thought that naturally support formality for open-ended, exploratory topics is hard
How can we synthesize “raw” unstructured inputs like papers/observations into complex structured representations?
A partial answer to this question is: with the right tools! It’s hard to do synthesis only in your head, especially when you get to the scale of ideas and sources that academics and researchers typically deal with. So it’s very helpful to have some kind of medium to do this externally (cf. distributed cognition, etc. – see Hollan, Hutchins & Kirsh, 2000).
Tools for thought are as old as computing itself; some might say as old as thinking itself! But as far as I’m concerned, tools for synthesis are still very much an open problem.
One crucial reason goes back to the requirement for formalism. We’ve seen that formal structure unlocks the most sophisticated levels of synthesis we want. Unfortunately, formal structure is also very tedious to specify, especially in the exploratory, open-ended domains where synthesis is most valuable. It’s devilishly tricky to make systems that support formalism which users will actually use (without a gun to their head).
Tools for synthesis that attempt to incorporate formalism typically have an extremely high barrier to entry and are an ongoing burden on the user. This overhead is exceedingly difficult to overcome for any kind of ongoing work.
These problems are well-documented in the classic paper Formality Considered Harmful: Experiences, Emerging Themes, and Directions on the Use of Formal Representations in Interactive Systems (Shipman & Marshall, 1999).
In brief, this paper identifies four classes of difficulties:
- Cognitive Overhead (aka Cognitive Load): often the task of specifying formalism is extraneous to the primary task, or is just plain annoying to do.
- Tacit Knowledge: if relevant information for developing formalism is tacit, asking people to formalize it will interrupt the task, with serious consequences for the quality of the work.
- Enforcing Premature Structure: people don’t want to commit until they’re sure what formalism is actually useful for their task (and what’s extraneous and only annoying).
- Situational Structure: Useful structures and formalisms vary significantly across people, situations, and tasks.
Fleshing out each of these ideas is out of the scope of this post. I encourage the interested reader to check out the Formality Considered Harmful paper (Shipman & Marshall, 1999)!
3. Incremental formalization can help ease the transition from informal unstructured data to formal structured representations
Fortunately, this line of research doesn’t only leave us with problems. Researchers also document a powerful design pattern that can help address the problem of formality: incremental formalization.
The basic intuition is described well by the Shipman & Marshall paper: users enter information in a mostly informal fashion, and then formalize only later in the task when appropriate formalisms become clear and also (more) immediately useful.
Here I note a few examples from that paper to help flesh out the concept (these are all older systems, mostly research systems, so unfortunately they’re not available to play with):
- In the Hyper-Object Substrate system, users enter mostly informal text initially, and the system recognizes patterns in the textual information to suggest possible formal attributes or relations for the underlying knowledge base, which the user can then accept/modify/reject as they wish (p. 347).
- Infoscope is a news reader system that suggests filters based on users’ reading patterns; this helps them make their goals explicit which can facilitate formalization after it emerges from their task behaviors (p. 347-348).
- VIKI is a spatial hypertext system that includes heuristic algorithms to find recurring visual/spatial patterns in layout of objects; users can use these to specify schemas if they wish.
Another more recent example comes from Van Kleek et al (2007): their Jourknow system includes a variety of features that can recognize formal structure (e.g., location, time, meeting information) from (relatively) unstructured notes in pidgin or more lightweight entry format, such as Notation3 (p. 195-197).
By now you may also start to think of other examples of this in production systems, such as Todoist recognizing key phrases like “today” to add formal date information to todos, or Gmail recognizing potential formal event data from an email when you create a calendar event while an email is open.
Incremental formalization addresses the cognitive overhead problem by spreading it throughout the task a bit more evenly, as well as removing it mostly from the earlier parts of the task, where minimal friction is needed to maximize exploration. It also helps with the premature and situational structure problems, since you don’t have to commit early on to a structure that may not serve you well (or even hurt your performance) later on.
4. Roam has the beginnings of (and high potential for powerful) incremental formalization
This idea is simple to understand, but very tricky to implement in practice. And I haven’t really seen many examples of systems trying do this for more complex tasks like synthesis (compared to recognizing calendar events, or attributes in an email, as in the Hyper-Object Substrate system). But it’s not intractable, as Roam shows!
Features that enable incremental formalization
The features in Roam that enable incremental formalization include:
- Unlinked references: initially write informally before you know a term is important, later turn into a formal link to a page
- Easily updated pages: don’t worry about precisely naming something at first. Let the meaning emerge over time and easily change it (propagating through all references). Connected to this are Andy Matuschak’s comments about contextual backlinks bootstrapping new concepts before explicit definitions come into play.
- More generally, in Roam, text is mixed with code (similar to Literate Programming, the paradigm from which Jupyter and other code-notebook systems have been inspired), but with a much deeper potential integration than simply interspersing text and code: each block is computable from the start. A simple example of this is the calc command, which grabs numbers from a block and makes them available for computation.
How does this work in action on Roam to enable synthesis?
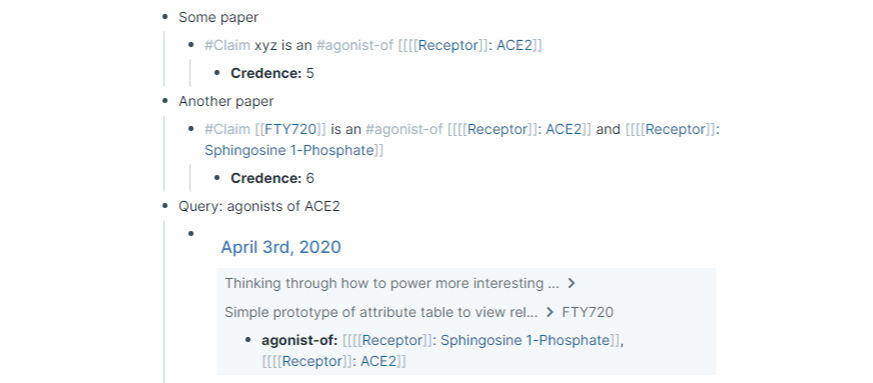
These incremental formalization features could enable Roam users to do really cool things to support synthesis. Here, I sketch out a couple of examples (you can view the Roam block for this here).
Formal propagation of belief values can be enabled in a lightweight way after the fact, using calc and block references.
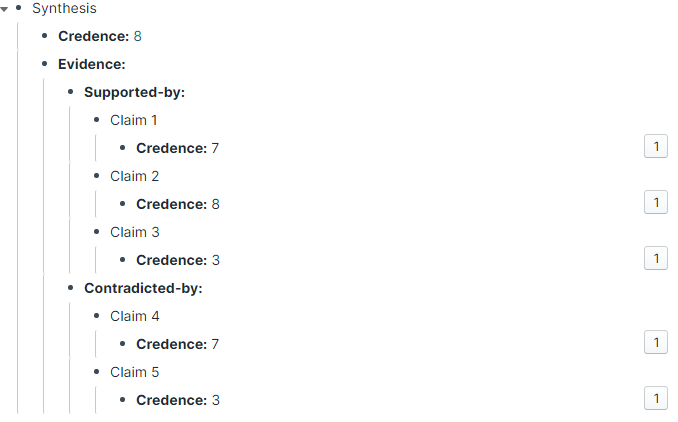
These credence attributes can be added after the fact, even argued about or propagated up from sliders (not currently supported natively), and then used to reason through how well supported or not a given claim is, with a simple calc call like:
![]()
As another example, adding in page tags (or adding them later via unlinked references) to claim blocks can enable powerful structured aggregation of queries not just by association but involving particular kinds of relationships. Importantly, these can be added later! Incremental formalization for the win!
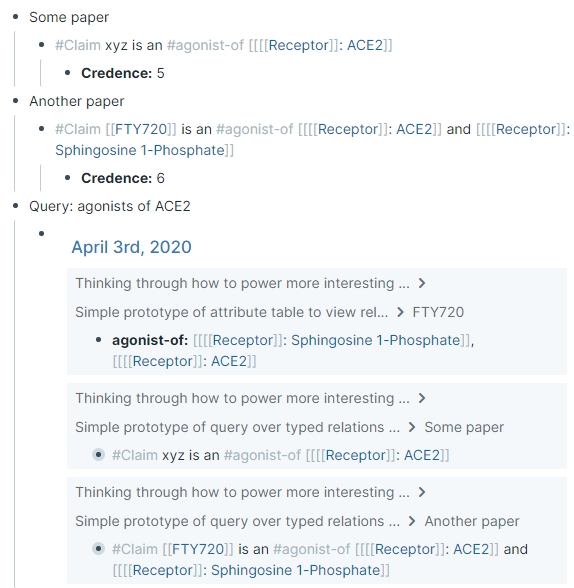
A lot of this power is still not yet fully realized; for example, attributes still can’t be used in as powerful a way as we want. But the potential is really there!
I’m already experiencing the value of formally tagging some claims and stitching them together into synthesis notes via block references and filtering. I’m eager to keep leveling up this process! If you’re interested, there is now a Literature Reviewing channel on the Roam Slack team (with Lukas Kawerau, Robert Haisfield, Stian Håklev and others), and Lukas Kawerau may be organizing more regular meetups.
Conclusion
In this short post, I explored why I think Roam is well-suited to support synthesis. I focused on the magic ingredient of incremental formalization, which infuses many aspects of Roam, and how yields great potential to overcome the user barrier of formality and unlock powerful modes of synthesis and reasoning.
The features I’ve described under the heading of incremental formalization are useful for synthesis, but I think they are also core to the magical experience of Roam: you don’t have to commit to a structure in the beginning (what file/cabinet does this go into? How should I tag it?). You simply write, and then formalize/link as you go to incrementally build your knowledge graph.
As I’ve said, there’s still a ways to go to fully unlock the potential of incremental formalization to power synthesis! Attributes could be extremely powerful, but their potential uses aren’t fully implemented in Roam yet. Little features like the data in sliders could become part of Bayesian belief networks. We could reason over the network structure in terms of the density/distribution of links, etc. But the sky (and apparently dev time) is the limit! I’m excited to see where it goes, and also eager to contribute my own ideas.
References
Hollan, J., Hutchins, E., & Kirsh, D. (2000). Distributed cognition: Toward a new foundation for human-computer interaction research. ACM Transactions on Computer-Human Interaction (TOCHI), 7(2), 174–196. doi.org/10.1145/353485.353487
Shipman, F. M., & Marshall, C. C. (1999). Formality Considered Harmful: Experiences, Emerging Themes, and Directions on the Use of Formal Representations in Interactive Systems. Computer Supported Cooperative Work (CSCW), 8(4), 333–352. doi.org/10.1023/A:1008716330212
Strike, Kenneth & Posner, George (1983). Types of synthesis and their criteria. In Spencer A. Ward & Linda J. Reed (eds.), Knowledge Structure and Use: Implications for Synthesis and Interpretation. Temple University Press. pp. 343–362.
Van Kleek, M., Bernstein, M., Karger, D. R., & Schraefel, M.C. (2007). Gui—Phooey!: The Case for Text Input. Proceedings of the 20th Annual ACM Symposium on User Interface Software and Technology, 193–202. doi.org/10.1145/1294211.1294247
(Joel Chan provides a tour of his Roam database and describes his knowledge management processes in this very interesting video – www.youtube.com/watch?v=A6PIrVZoZAk.)

