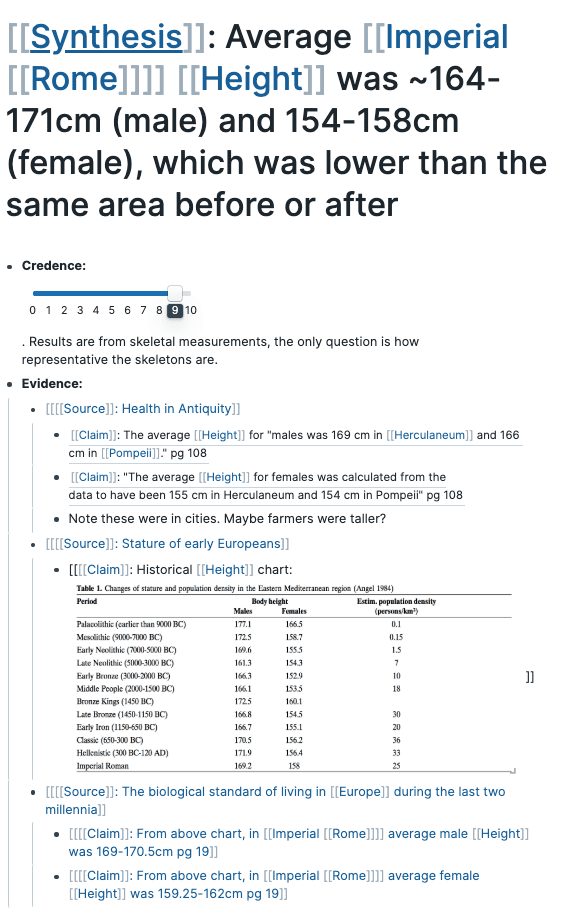
Roam is a new note taking app for “networked thoughts”, and the tool and community that inspired me to begin writing my newsletter. One of the most impressive use-cases for Roam is Elizabeth Van Nostrand’s approach to extremely careful reading of history books. She showcased her approach during the San Francisco Roam meetup in January: She will take a history book, for example about the Roman empire, and try to extract every single claim that is made. Things like: The average height in imperial Rome was 164-171 cm for men. I know that I would just pass this by, if I was reading the same book, but she asks herself: How can we know? She looks at the evidence the author presents, follows their citations, but also reads across other sources.
Keeping track of this is complex, but she uses things like tags and block embeds in Roam, which lets her easily filter for all claims from a certain book, all evidence pertaining to a certain claim, etc.
This approach is certainly extreme, both the level of detail spent on a single fact, and that she focuses on facts that don’t seem to be highly controversial or “important” in our lives. However, given the amount of carelessness we see in books, we probably need much more of this kind of deep-dives. And ideally, once we’ve established this very peculiar fact (which is not likely to be featured in Wikipedia), ideally all future publications would directly cite this discussion, and if they have contradictory or supporting evidence, add it to a central repository (or somehow link to it so that they get caught in backlinks), so that we keep building our knowledge.
But if we have all these statements that we cannot be 100% sure about, can we really build any logical tree of inference on top of them?
Bayesian reasoning to the rescue
Right now, Elizabeth’s database, although open, is not hugely useful to the rest of the world, and the Roam technology is far from an interlinked knowledge base. But listening to the interview between Tiago Forte and Conor White-Sullivan (Roam founder), there is no doubt about the ambition to get there. The Roam White Paper (which is somewhat out of date, but describes the initial vision), includes this intriguing piece:
While this is a simple calculation, the strength of Bayesian reasoning is that it breaks down seemingly insurmountable problems into small pieces. Even where no data are available, successive layers of estimates can still provide useful refinements to the confidence levels of various outcomes. By incorporating this framework into the defined relationships between nodes, revisions to the weightings at any point in the network will automatically populate throughout the knowledge graph.
Bayesian probability also provides a framework for decision-making. By estimating the costs and tradeoffs of various options, users can calculate which pathway provides the highest expected value. Again, the quality of the decisions can be refined by successive layers of evidence for and against, even when the weightings are simple estimates of personal preference. An evaluation matrix allows someone to integrate a great deal of information into the final decision, rather than defaulting to simple heuristics.
So perhaps we can imagine a future where we collect evidence, build up a collective base of understanding around specific facts, and build chains of reasoning on top of these facts in a way such that our uncertainty can propagate (and we can recalculate all values once evidence is added to a small building-block).
Imagine how a fact such as the average height in Rome could be a small building block for Yuval Noah’s Sapiens. Can we instantly recalculate how damaging it is to his overall argument if evidence is suddenly found showing that all Romans were 2 meters tall?
This is taken from Stian’s Networked Thought and Learning newsletter which covers Roam, tools for thought, networks and semantics, etc.